1 名词解释
Inspire采用事件数据模型,具体参见《事件模型》章节,这里简单描述几个概念。
- 事件(Event):基本的事件可定义为某个主体在某一时刻,发生了某件事、产生了某个动作或出现了某个状态。
- 事件属性(Event Property):发生某一事件的同时,除了事件必要的元素外,其它用于描述该事件的附加属性数据。后文简称为Property。
- 数据集(collection):数据集是一个逻辑概念,用于将具有相同或相似属性的事件数据归为一类。可类比RDBS的table。
- 主体属性(Actor Profile):用于描述主体基本固定不变的特征数据。后文简称为Profile。
- AK/SK:AbleCloud的开发秘钥Access Key,Secret Key,在调用API请求时用于做开发者签名认证之用。
2 数据写入
AbleCloud Inspire提供schema-less的写入方式,用户不用事先预定义表格的格式,直接写入数据。Inspire会自动识别您所写数据中的所有属性(Property),并且识别出哪些属性适合做维度分析,所有的这些工作都由Inspire自动进行,大大简化了开发者的工作量。在第一条事件数据到达Inspire平台时如果该Collection不存在,平台会自动为厂商创建该Collection。
2.1 RESTful API
Inspire原生提供RESTful形式的API接口,请求的参数传递以及返回结果,除了使用HTTP头域字段之外,均采用JSON作为数据交互格式。
2.1.1 基础说明
请求URL
请求URL的完整pattern为:{host}/{service}/{version}/{method}?[parameter]。其中parameter可选,也可由请求的body传输。
| 字段 | 取值 | 说明 |
|---|---|---|
| host | www.ablecloud.cn:5000或test.ablecloud.cn:5000 | 生产环境使用www,测试环境使用test |
| service | zc-queryengine | 固定为该值 |
| version | v1 | 当前是v1版本 |
| method | write/profile/count/... | Inspire提供的各种方法,后文详述 |
| parameter | 可选 |
HTTP方法
当前,所有的API接口只支持POST方法。
公共头域
出于对数据的隔离性和安全性考虑,我们将不同厂商的数据分开存储,因此后台需要对厂商进行识别。这里我们使用主域ID来区分数据,因此需要提供的头域如下:
| 字段 | 是否必须 | 类型 | 说明 |
|---|---|---|---|
| Content-Type | 是 | string | 必须为text/json |
| X-Zc-Major-Domain | 是 | string | 厂商的主域名,登陆平台可看到 |
| X-Zc-Sub-Domain | 是 | string | 厂商的子域名,只用于验证签名,该厂商任一合法子域均可,无需子域时填入空字符串"" |
| X-Zc-Developer-Id | 是 | int | 厂商的开发者ID |
| X-Zc-Access-Key | 是 | string | 厂商开发者的access key |
| X-Zc-Timestamp | 是 | string | 生成签名时刻的时间戳,自1970-01-01 00:00:00以来的UTC秒数 |
| X-Zc-Timeout | 是 | string | 签名自X-Zc-Timestamp开始的超时时间,单位秒 |
| X-Zc-Nonce | 是 | string | 生成签名的随机字符串 |
| X-Zc-Developer-Signature | 是 | string | 生成的签名 |
注:AbleCloud为开发者提供两种权限的AK/SK,登录控制台后可在“个人中心”查看。建议事件写入API使用“可写秘钥”签名防止秘钥泄露,查询API使用“可读写秘钥”签名。
主域:厂商在平台注册时为厂商分配的唯一标识。子域:为同一厂商下不同类型的产品分配的唯一标识。如果不区分产品,则子域可为空。
签名算法
java版本的开发者签名算法代码如下,其它语言可参考实现即可:
public class ACSigner {
private static final Logger logger = LoggerFactory.getLogger(ACSigner.class);
private static final String ENCODING = "UTF-8";
private static final String HASH = "HmacSHA256";
/**
* 组装用于签名的完整字符串,必须按照代码中的顺序拼接各个字段。
*
* @param developerId 对应公共头域X-Zc-Developer-Id的值
* @param majorDomain 对应公共头域X-ZC-Major-Domain的值
* @param subDomain 对应公共头域X-Zc-Sub-Domain的值
* @param method 请求URL中的method字段的值,而不是HTTP的'GET'等方法
* @param timestamp 对应公共头域X-Zc-Timestamp的值
* @param timeout 对应公共头域X-Zc-Timeout的值
* @param nonce 对应公共头域X-Zc-Nonce的值
*
* @return 用于签名的字符串
*/
public static String genSignString(long developerId, String majorDomain,
String subDomain, String method,
long timestamp, long timeout, String nonce) {
String stringToSign = String.valueOf(timeout) +
String.valueOf(timestamp) +
nonce +
String.valueOf(developerId) +
method +
majorDomain +
subDomain;
return stringToSign;
}
/**
* 通过拼接好的字符串,生成最终的签名字符串
*
* @param sk 即Secret Key,登陆平台后获取,注意需要和Access Key配对
* @param stringToSign 通过genSignString方法生成的用于签名的字符串
*
* @return 签名字符串
*/
public static String genSignature(String sk, String stringToSign) {
String signature = "";
try {
String encodedSign = URLEncoder.encode(stringToSign, ENCODING);
try {
Mac mac = Mac.getInstance(HASH);
mac.init(new SecretKeySpec(sk.getBytes(ENCODING), HASH));
byte[] hashData = mac.doFinal(encodedSign.getBytes(ENCODING));
StringBuilder sb = new StringBuilder(hashData.length * 2);
for (byte data : hashData) {
String hex = Integer.toHexString(data & 0xFF);
if (hex.length() == 1) {
// append leading zero
sb.append("0");
}
sb.append(hex);
}
signature = sb.toString().toLowerCase();
} catch (Exception e) {
logger.warn("sha256 exception for[" + sk + "," + stringToSign + "]. e:", e);
}
} catch (UnsupportedEncodingException e) {
logger.warn("encode error, string[" + stringToSign + "] e:" + e);
}
return signature;
}
}
2.1.2 数据格式
无论是Event数据还是Profile数据,均通过json格式组织,除了个别内定字段需要按要求指定字段名外,具体的数据可以为任意嵌套的合法json格式。
我们前面提到过,整个分析系统基于事件数据模型,因此每条Event Data都应该具有发生时刻属性。类似于事件发生时刻这种属性,必须按AbleCloud预定的格式填写,该属性在写入的data中,需要在event域,且名为timestamp,形如:
"event": {
"timestamp": "2015-07-03 18:38:03.262649+0800"
}
考虑到每条Event Data均具有该属性,用户可以不用显示指定该属性值,Inspire默认会为每条数据生成当前的timestamp并自动补充到其写入的data上。不过,这种默认为当前时刻的timestamp不适用于历史数据的导入,因此如果用户需要导入历史数据,仍然需要由用户显示的指定上述"event.timestamp"。这里+0800是时区信息,在这里代表东八区。
注:所有evnet数据写入Inspire后,会转成UTC时间保存。
类似timestamp字段,Inspire当前支持的保留字段如下:
| 字段 | 类型 | 说明 |
|---|---|---|
| event.timestamp | string | 如果Client不指定该字段,平台会取数据到达平台的服务器时间 |
| event.ip | string | 如果Client指定了ip字段,平台会自动将ip地址转换成国家、省、市地址 |
为了使开发者的灵活度更大,我们支持完整的多层JSON格式,而不是只支持扁平的一层结构。比如对于user域会有name属性,product域也可能有name属性,可以如下方式组织写入的购买事件属性(部分片段):
{
"user": {
"name": "andy",
"gender": "male"
},
"product": {
"name": "sony tv",
"price": 5999
}
}
2.1.3 Event写入
在您的项目中实时过程中,只需要简单调用事件写入接口,便可以在任何地方记录用户或设备的任意事件。比如我们可以在APP端调用接口记录用户的登录、使用APP的行为;可以在硬件端调用接口汇报设备的状态数据;也可以在后台服务调用接口记录经过一定处理或ETL后的事件数据。
从时效性和性能两方面考虑,Inspire分别提供了单条和批量写入接口,下面分别详细介绍。
2.1.3.1 单条Event写入
方法
URL中的方法为write。
请求
- 在URL中的参数部分指定数据集名称,形如collection={collection_name}
- 在body中写入json格式的具体事件数据内容
响应
无具体的content,根据响应的http头域判断:
| 字段 | 类型 | 值 | 说明 |
|---|---|---|---|
| X-Zc-Msg-Name | string | X-Zc-Ack | 成功 |
| X-Zc-Msg-Name | string | X-Zc-Err | 失败 |
示例
curl -X POST http://test.ablecloud.cn:5000/zc-queryengine/v1/write?
collection=purchase \
-H "Content-Type:text/json" \
-H "X-Zc-Major-Domain-Id:1" \
-d '{
"event":{
"timestamp": “2015-10-10 18:18:18.000000+0800”
},
"uid": 1,
"did": "abc123",
"price": 45.9,
"channel": "jd"
}'
说明:本次调用write方法将用户id为1的用户购买一个设备id为abc123的设备事件写入数据分析平台Inspire,并且购买价格为45.9元,渠道来自京东。随着业务的发展,对相同的事件集中数据,如果需要记录更多的事件属性,则在新写入的事件数据中直接增加新的内容(增加json的字段)即可,Inspire会自动识别并保存新增部分。
注:在写入事件数据时,事件中的主体(Actor)标识字段名需遵从Inspire规定,Inspire内定了三类主体标识字段,
uid、did和pid,分别标识用户id,设备id和手机id。主体标识字段名必须按规定填写,字段取值类型可自定义。事件的其它数据自定义,合法json格式就可以。
2.1.3.2 批量Event写入
方法
URL中的方法为batch_write。
请求
- 在URL中的参数部分指定数据集名称,形如collection={collection_name}
- 在body中写入json格式的具体事件数据内容
响应
无具体的content,根据响应的http头域判断:
| 字段 | 类型 | 值 | 说明 |
|---|---|---|---|
| X-Zc-Msg-Name | string | X-Zc-Ack | 成功 |
| X-Zc-Msg-Name | string | X-Zc-Err | 失败 |
示例
curl -X POST http://test.ablecloud.cn:5000/zc-queryengine/v1/batch_write?
collection=purchase \
-H "Content-Type:text/json" \
-H "X-Zc-Major-Domain-Id:1" \
-d '{
"batch": [
{
"event":{
"timestamp": “2015-10-10 18:18:18.000000+0800”
},
"uid": 1,
"did": "abc123",
"price": 45.9,
"channel": "jd"
},
{
"event":{
"timestamp": “2015-10-10 18:19:18.000000+0800”
},
"uid": 2,
"did": "abc124",
"price": 55.9,
"channel": "tmall"
}
]
}'
说明:本次调用batch_write一次性写入了两条购买事件到Inspire中。
注:body中json格式事件数据,需要将多条事件放入key为
batch的数组里。多条事件数据的timestamp需要显示指定,否则服务器端会为多条事件分配相同的时间。batch中的事件条数没有限制,根据业务需要自行决定。
2.1.4 Profile写入
为了方便基本固定不变属性的管理,AbleCloud Inspire提供了Profile写入接口,通常情况下,同一id所标识的Profile只需写入一次即可。随着业务的发展,对相同类型的Profile,如果需要记录更多的属性,则在新写入的Profile数据中直接增加新的内容(增加json的字段)即可,Inspire会自动识别并保存新增部分。
和Event数据一样,提供了单条和批量写入接口。
2.1.4.1 单条Profile写入
方法
URL中的方法为profile。
请求
- 在URL中的参数部分指定profile的类型,形如
type=actor - 在body中写入json格式的具体profile内容
响应
无具体的content,根据响应的http头域判断:
| 字段 | 类型 | 值 | 说明 |
|---|---|---|---|
| X-Zc-Msg-Name | string | X-Zc-Ack | 成功 |
| X-Zc-Msg-Name | string | X-Zc-Err | 失败 |
示例
curl -X POST http://test.ablecloud.cn:5000/zc-queryengine/v1/profile?
type=object \
-H "Content-Type:text/json" \
-H "X-Zc-Major-Domain-Id:1" \
-d '{
"id": "abc123",
"product": "水杯"
}'
说明:本次调用profile方法,写入了一个类型为object的profile到Inspire中,其id为abc123,产品为水杯。
注:URL中的type类型当前支持
actor、object和mobilephone三种,分别标识用户、设备和手机。Profile中必须要有id字段,且字段名固定为id,取值类型可自定义。Proflie的其它数据自定义,合法json格式就可以。
2.1.4.2 批量Profile写入
方法
URL中的方法为batch_profile。
请求
- 在URL中的参数部分指定profile的类型,形如
type=actor - 在body中写入json格式的具体profile内容
响应
无具体的content,根据响应的http头域判断:
| 字段 | 类型 | 值 | 说明 |
|---|---|---|---|
| X-Zc-Msg-Name | string | X-Zc-Ack | 成功 |
| X-Zc-Msg-Name | string | X-Zc-Err | 失败 |
示例
curl -X POST http://test.ablecloud.cn:5000/zc-queryengine/v1/batch_profile?
type=object \
-H "Content-Type:text/json" \
-H "X-Zc-Major-Domain-Id:1" \
-d '{
"batch": [
{
"id": "abc123",
"product": "水杯1"
},
{
"id": "abc124",
"product": "水杯2"
}
]
}'
说明:本次调用batch_profile一次性写入了两个设备的profile数据到Inspire中。
注:body中json格式Profile数据,需要将多条事件放入key为
batch的数组里。batch中的Profile条数没有限制,根据业务需要自行决定。
2.2 Android SDK
2.2.1 开发准备
2.2.1.1 SDK发布库
AbleCloud发布的SDK为ac-inspire-android-1.0.0.jar
注:把jar包拷贝到工程的libs目录下并设置依赖。
2.2.1.2 开发环境设置
以下为 AbleCloud Android SDK 需要的所有的权限,请在你的AndroidManifest.xml文件里的<manifest>标签里添加。
<uses-permission android:name="android.permission.INTERNET"/>
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"/>
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE"/>
<uses-permission android:name="android.permission.READ_PHONE_STATE"/>
2.2.1.3 配置文件初始化
在你的AndroidManifest.xml文件里的<application>标签里添加。
<!-- [Required] 对应"产品管理->产品列表->主域名" -->
<meta-data android:name="major-domain" android:value="ablecloud"/>
<!-- [Required] 对应"个人信息->个人信息->开发者ID" -->
<meta-data android:name="developer-id" android:value="2"/>
<!-- [Required] 对应"密钥对管理->全部密钥对",选择已启用的任意一对。-->
<meta-data android:name="access-key" android:value="1ce883b840f00fef8086d214e6455f58"/>
<meta-data android:name="secret-key" android:value="15ffa41c403a46ae80dffffdc4277a09"/>
<!-- [Optional] 环境设置,默认值为0(0测试环境 1正式环境) -->
<meta-data android:name="mode" android:value="0"/>
<!-- [Optional] 地域设置,默认值为0(0北京地区 1东南亚地区 2华东地区) -->
<meta-data android:name="region" android:value="0"/>
<!-- [Optional] SDK缓存日志的最大条目数,超过此值将立即进行发送,默认值为100 -->
<meta-data android:name="bulk-size" android:value="100"/>
<!-- [Optional] SDK发送日志的最大时间间隔,单位毫秒,默认值为60 * 1000 (60秒) -->
<meta-data android:name="flush-interval" android:value="60000"/>
<!-- [Optional] SDK本地缓存数据库最小值,单位 Byte,默认为20 * 1024 * 1024 (20MB) -->
<meta-data android:name="minimum-database-limit" android:value="20000000"/>
2.2.2 SDK使用
2.2.2.1 初始化SDK
在MainActivity.java主activity中,获得SDK单例对象:
private Inspire inspire ;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
inspire = Inspire.getInstance(this);
}
@Override
protected void onDestroy() {
super.onDestroy();
inspire.flush();
}
注:在退出app时,通过调用
flush()接口将未同步的事件同步到云端。
2.2.2.2 用户注册
在用户注册/登录成功时,需要调用以下接口设置用户的id
/**
* 用户注册/登录(退出登录重新登录时需重新调用该接口)
*
* @param id 唯一标识userId,仅支持long/string
*/
public void identify(Object id) {}
2.2.2.3 用户/设备Profile
类似用户/设备扩展属性一样,通过设置以下接口将uid/did与properties里的属性相关联;如以下场景,在app的个人中心里用户选择性别、年龄等后,点击确定调用以下接口设置该用户相关属性等到云端。
/**
* 设置用户/设备的一个或多个Profile
* Profile如果存在,则覆盖更新;否则,新创建。
*
* @param type 类型,表示用户表/设备表
* @param id 唯一标识,如userId/deviceId
* @param properties 用户/设备属性列表
*/
public void setProfile(ACProfileType type, Object id, JSONObject properties) throws JSONException {}
2.2.2.4 追踪事件
设置用户ID后,可通过track()接口记录事件。其中did为预留字段,如果事件涉及设备属性相关,则需要在properties中添加did字段(注意:did为设备物理ID)。
/**
* 调用track接口,追踪一个不带属性的事件
*
* @param eventName 事件的名称
*/
public void track(String eventName) throws JSONException {}
/**
* 调用track接口,追踪一个带有属性的事件
*
* @param eventName 事件的名称
* @param properties 事件的属性,uid/did为预留字段,代表用户id/设备物理id;其中uid通过identify接口设置,did根据实际情况事件是否有设备id设置
*/
public void track(String eventName, JSONObject properties) throws JSONException {}
2.2.2.5 事件同步
为了节省客户端的网络流量,Android SDK会将数据缓存在本地,经过一段时间或积累了一定数据量后批量压缩发送至AbleCloud大数据分析平台,用户可调用flush()接口,强制同步数据到Inspire。
2.3 iOS SDK
2.3.1 集成准备
2.3.1.1 获取AccessKey & SecretyKey
集成AbleCloud SDK之前,您首先需要到AbleCloud官网注册,获得Ak&Sk
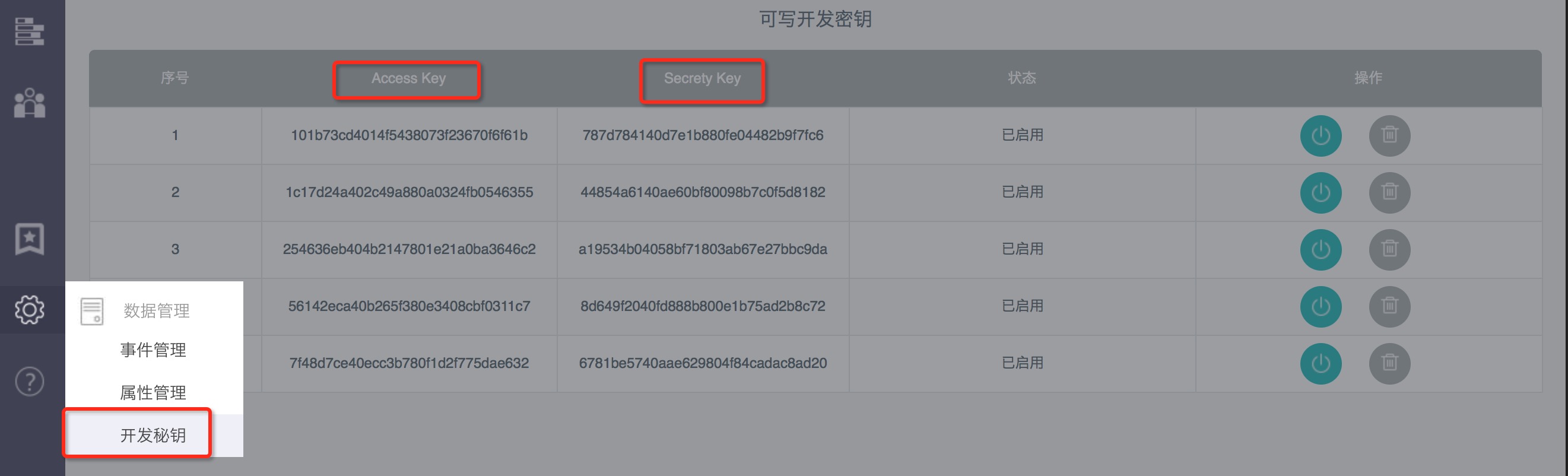
2.3.1.2 下载SDK
下载分析SDK并解压缩。
2.3.1.3 导入SDK
- 请在你的工程目录结构中,右键选择
Add->Existing Files…,选择文件Inspire.a,Inspire.h,或者将这两个文件拖入Xcode工程目录结构中,在弹出的界面中勾选Copy items if needed, 并确保Add To Targets勾选相应的target 。 如下图:
- 添加依赖框架(Framework)和编译器选项
TARGETS-->Build Phases-->Link Binary With Libraries--> + --> libz.tbd & libsqlite3.tbd - 编译项目(cmd + b)
2.3.2 基本功能集成
2.3.2.1 配置AppDelegate.m
AppDelegate.m 的配置主要包括配置开发地区和模式,设置启动参数两部分,代码示例如下:
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions {
//设置开发环境
//测试开发阶段使用环境
[Inspire setMode:InspireModeTest Region:InspireRegionChina];
//上线正式环境使用, Region请根据实际情况自己选择, 详见 Inspire.h
[Inspire setMode:InspireModeRouter Region:InspireRegionChina];
//设置启动参数
[Inspire startWithMajorDomain:<#majorDomain#>
subDomain:<#subDomain#>
developerId:<#developerId#>
accessKey:<#accessKey#>
secretyKey:<#secretyKey#>;
return YES;
}
其中,majorDomain / subDomain / developerId / accessKey / secretyKey 请到服务控制台查询。
2.3.2.2 iOS9中ATS配置
由于iOS9引入了AppTransportSecurity(ATS)特性,要求App访问的网络使用HTTPS协议,如果不做特殊设置,http请求会失败,所以需要开发者在工程中增加设置以便可以发送http请求,如下:
在info plist中增加字段:
< key>NSAppTransportSecurity< /key>
< dict>
< key>NSAllowsArbitraryLoads< /key>
< /dict>
配置完后如图所示:

2.3.2.3 设置自动上传时间
为了节省客户端的网络流量,SDK会将数据缓存在本地,经过一段时间后批量压缩发送至AbleCloud 大数据分析平台。 用户可调用flush()接口,立刻同步数据到分析平台,
[Inspire flush];
也可通过调用以下接口设置默认发送时间间隔:
[Inspire setFlushInterval:<#flushTime#>];
注:上传时间间隔默认是60s。
2.3.2.4 用户注册
在用户注册/登录成功时,需要调用以下接口设置当前用户的id, 目前支持NSString 和 NSNumber 格式的id
/// 设置当前用户的id
+ (void)identify:(id)identifier;
2.3.2.5 用户/设备Profile
类似用户/设备扩展属性一样,通过设置以下接口将userId/deviceId与properties里的属性相关联。
如以下场景,在app的个人中心里用户选择性别、年龄等后,点击确定调用以下接口设置该用户相关属性等到云端
/// 设置用户/设备的一个或多个Profile
/// Profile如果存在 则覆盖更新 否则 新创建
///
/// @param type 类型,表示用户表/设备表
/// @param id 唯一标识,如userId/deviceId
/// @param properties 用户/设备属性列表,需跟后台设置的参数一致
+ (void)setProfile:(ACProfileType)type identifier:(id)identifier properties:(NSDictionary *)properties;
示例
//属性字典,字段名要和后台设置的一致
NSDictionary *properties = @{
@"name": @"yourName",
@"age": @"yourAge",
@"sex": @"yourSex",
};
[Inspire setProfile:ACProfileTypeUser identifier:@"your ID" properties:properties];
注:ACProfileTypePhone 事件由SDK默认处理,不建议开发者使用。
2.3.2.6 追踪事件
设置用户ID后,可通过 track() 接口记录事件;其中uid/pid为预留字段,开发者不要使用。如果事件涉及设备属性相关,则需要在properties中添加did字段(注意:did为设备物理ID)
/// 追踪不带属性的事件
///
/// @param eventName 事件名称
+ (void)track:(NSString *)eventName;
/// 追踪事件
///
/// @param eventName 事件名称
/// @param properties 自定义事件属性, 需要跟后台填写的字段名一致
+ (void)track:(NSString *)eventName properties:(NSDictionary *)properties;
示例:
//记录程序启动事件
[Inspire track:@"appStart"];
//自定义设备属性,记录对应操作
[Inspire track:@"yourEventName" properties:@{@"name": @"yourName", @"did":@"yourDid"}];
3 数据分析
3.1 RESTful API
Inspire为方便用户使用,提供了多种分析模型,如简单的aggregation、distribution,也提供了复杂的cohort、funnel、session等分析,下面将详细介绍各个分析API的详细用法。
3.1.1 公共参数
3.1.1.1 Timeframe
Timeframe指的是一个时间段,你可以在该时间段内进行各种分析统计。前面提到,事件数据的一个特征便是具有时间属性,因此大多数统计都将基于时间维度来进行。比如查询最近一天、某一个月的注册用户数等。如果不指定timeframe,分析将在所有的事件数据上进行。
AbleCloud Inspire提供的timeframe时间精度为0.000001秒,即精确到微秒。Timeframe可分为相对时间和绝对时间。
绝对时间
绝对时间需要指定两个时间点start和end,表示[start ~ end]这一时间段。时间点目前支持如下形式: 2015-08-08 11:11:11.000000+0800,其中+0800为时区信息,这里为东八区
"timeframe": {
"start": "2015-07-01 18:38:03.262649+0800",
"end": "2015-07-03 18:38:06.000000+0800"
}
相对时间
从当前时间往前推移一个历史时间段,如当前一分钟、过去两小时等。相对时间格式如下:
"timeframe": "{rel}_{n}_{units}"
其各字段含义:
| 字段 | 取值 | 含义 |
|---|---|---|
| rel | this或previous | this表示包含当前时间,previous标识之前一段完整的时间 |
| n | 任意大于0的数 | 表示多少个时间单位 |
| units | 时间单位 | 支持seconds、minutes、hours、days、weeks、months和years |
支持的this相对时间如下:
| timeframe | 说明 |
|---|---|
| this_{n}_seconds | 表示当前秒(不一定完整)和之前完整n-1秒这一时间段 |
| this_{n}_minutes | 表示当前分钟(不一定完整)和之前完整n-1分钟这一时间段 |
| this_{n}_hours | 表示当前小时(不一定完整)和之前完整n-1小时这一时间段 |
| this_{n}_days | 表示当前天(不一定完整)和之前完整n-1天这一时间段 |
| this_{n}_weeks | 表示当前星期(不一定完整)和之前完整n-1星期这一时间段 |
| this_{n}_months | 表示当前月(不一定完整)和之前完整n-1月这一时间段 |
| this_{n}_years | 表示当前年(不一定完整)和之前完整n-1年这一时间段 |
支持的previous相对时间如下:
| timeframe | 说明 |
|---|---|
| previous_{n}_seconds | 表示当前秒前完整的n秒这一时间段。如当前为2015-07-07 07:15:30.262649+0800,previous_5_seconds则表示[2015-07-07 07:15:25.000000+0800 ~ 2015-07-07 07:15:30.000000+0800]这5秒的时间段 |
| previous_{n}_minutes | 表示当前分钟前完整的n分钟这一时间段。如当前为2015-07-07 07:15:30+0800,previous_3_minutes则表示[2015-07-07 07:12:00.000000+0800 ~ 2015-07-07 07:15:00.000000+0800]这3分钟的时间段 |
| previous_{n}_hours | 表示当前小时前完整的n小时这一时间段。如当前为2015-07-07 07:15:30+0800,previous_5_hours则表示[2015-07-07 02:00:00.000000+0800 ~ 2015-07-07 07:00:00.000000+0800]这3小时的时间段 |
| previous_{n}_days | 表示当前天前完整的n天这一时间段。如当前为2015-6-11 07:15:30+0800,previous_3_days则表示[2015-6-8 00:00:00.000000+0800 ~ 2015-6-11 00:00:00.000000+0800]这三天的时间段 |
| previous_{n}_weeks | 表示当前星期前完整n星期这一时间段。如当前为星期四,previous_2_weeks表示[之前第三个星期天的00:00:00.000000+0800 ~ 当前星期天的00:00:00.000000+0800]这两周时间段 |
| previous_{n}_months | 表示当前月前完整n月这一时间段。如当前为2015-6-11,previous_2_months表示[2015-4-1 00:00:00.000000+0800 ~ 2015-5-31 23:59:59.000000+0800]这2月时间段 |
| previous_{n}_years | 表示当前年前完整n年这一时间段。如当前为2015-6-11,previous_2_years表示[2013-1-1 00:00:00.000000+0800 ~ 2014-12-31 23:59:59.000000+0800]这2年时间段 |
3.1.1.2 Timezone
用于指定时区,比如"Asia/Shanghai",查询的时候Inspire根据此时区信息以便获取到正确Timeframe中的数据。并且必须和timeframe中相应的时区匹配,比如"Asia/Shanghai"对应为东八区,那么timeframe内的时区信息为+0800。
注:如果不指定timezone,则默认使用UTC时间。
3.1.1.3 Interval
interval表示时间间隔。在统计中经常用到,结合timeframe和interval,其查询结果往往是一个结果系列。如查询某一天内每小时的注册用户数。当前支持时间间隔格式如下:
"interval": "every_{n}_{units}"
说明
| 字段 | 取值 | 含义 |
|---|---|---|
| n | 任意大于0的数 | 表示多少个时间单位 |
| units | 时间单位 | 支持seconds、minutes、hours、days、weeks、months和years |
注:不是所有的units都支持任意的n值,需符合当前所支持的对应关系。
n和units的对应关系
| n取值 | 支持的units |
|---|---|
| 任意大于0的数(包含1) | seconds、minutes、hours、days |
| 1 | weeks、months、years |
3.1.2 Group by
Group by用于将查询进行分组后再聚合,如可用于统计设备在各个省份的激活情况,group_by定义如下:
"group_by":["province"]
注:Inspire支持按多个属性进行分组,因此group by的取值为json数组格式。
由于数据分析平台将所有数据分为三类,一类是主体actor数据,一类是客体object数据,最后一类是事件数据。举个例子:
小明买了一部手机。其中小明是主体actor,手机是客体object,购买这个事件是事件数据。小明这个人本身的个人信息比如名字会记录在主体actor profile表中,这张表中没有事件时间戳这个属性。手机本身的属性比如型号等记录在客体object profile表中,这张表也没有事件时间戳这个属性。在购买事件表中会存储购买这个事件。
那么做group by的时候,需要执行每个group by的列是属于actor类型的列还是object类型的列,还是事件类型的列,取值分别为actor, object和event. 如果不指定group_by_type属性,那么默认情况为event,多个group by列中,只要有任何一个列是非event列,那么就必须指定group_by_type属性。
"group_by_type" : ["object"]
注:可以看出,多数情况下
group_by和group_by_type接合一起使用。
3.1.3 Order by
Order by用于对结果进行排序,如按区域销售量的降序排序。定义如下两种形式:
"order_by": {
"property": "foo",
"reverse": true
}
或
"order_by": {
"property": "#"
}
说明
| 字段 | 含义 | 说明 |
|---|---|---|
| property | 按此属性进行排序 | 有两种取值:1.在collection中存在属性;2.单个井号"#",表示按聚合函数得到的结果排序 |
| reverse | 是否逆序 | 可选,如果不指定默认按升序排序 |
注:默认按当前只支持单个order by item。
3.1.4 Limit
Limit用于限制返回的结果数,其定义如下:
"limit": 10
注:结合order by和limit,可以实现top n的分析功能。
3.1.5 Filters
Filters用于过滤需要分析的数据,其单个值的json格式定义如下:
"property_name": "tmperature",
"operator": "gte",
"property_value": 38.5
真正的查询请求中的filters支持AND和OR的各种组合,但是其都可以归约成
(A AND B) OR (C AND D) OR (E AND F)
或者
(A OR B) AND (C OR D) AND (E OR F)
故,filters定义为以下二级结构形式,以下是一个稍微复杂点的filters
"filters": {
"relation": "AND",
"agg_filters": [
{
"relation" : "OR",
"property_filters": [
{
"property_name": "temperature",
"operator": "gte",
"property_value": 38.5
},
{
"property_name": "user.id",
"operator": "in",
"property_value": [
1,
2,
3
]
}
]
},
{
"relation" : "OR",
"property_filters": [
{
"property_name": "action",
"operator": "eq",
"property_value": "on"
},
{
"property_name": "device.id",
"operator": "in",
"property_value": [
4,
5,
6
]
}
]
}
]
}
以上json表示的filters为 ("temperature" >= 38.5 OR "user.id" in (1,2,3)) AND ("action" = "on" OR "device.id" in (4,5,6))。
可以看出,有两层结构,最外面那个relation是一级relation(在这里是AND), agg_filters这个数组里所有的元素之间的关系就是一级relation,对于agg_filters中的每个元素,本身也可以是一个有多个filter级联起来的filter,这里的级联就是二级relation,在上面例子中,agg_filters数组有两个元素,每个元素都是由两个简单的filter组成的,filter之间的关系是OR。
注:不管是一级relation还是二级relation,取值都只能为AND和OR。relation在某些情况下也可以省略。
下面说说简单的filters如何表示。
示例一:"temperature" >= 38.5
"filters": {
"agg_filters": [
{
"property_filters": [
{
"property_name": "temperature",
"operator": "gte",
"property_value": 38.5
}
]
}
]
}
当某一级relation没有指定的时候,相应的数组必须只有一个元素。例子中,一级relation没有指定,那么agg_filters中只有一个元素,对于agg_filters中的唯一这个元素,由于二级relation没有指定,那么后续的property_filters数组里面也只有一个元素。
示例二:("temperature" >= 38.5 OR "user.id" in (1,2,3))
"filters": {
"agg_filters": [
{
"relation" : "OR",
"property_filters": [
{
"property_name": "temperature",
"operator": "gte",
"property_value": 38.5
},
{
"property_name": "user.id",
"operator": "in",
"property_value": [
1,
2,
3
]
}
]
}
]
}
说明
| 字段 | 含义 | 说明 |
|---|---|---|
| property_name | 将要过滤的属性 | 必须在collection中存在 |
| operator | 过滤比较操作符 | 支持多种,详述见下表 |
| property_value | 过滤条件,即属性的值 | 该值将在property_name指定的属性上进行比较 |
operator说明
| operator | 说明 |
|---|---|
| eq | equal to,即等于 |
| ne | not equal to,即不等 |
| lt | less than,即小于 |
| lte | less than or equal to,即小于等于 |
| gt | greater than,即大于 |
| gte | greater than or equal to,即大于等于 |
| contains | 包含,用于字符串模糊匹配 |
| not_contains | 不包含,用于字符串模糊匹配 |
| in | 在...中,此时property_value为json数组形式,如[2,4,5] |
| between | 值在某个范围内,此时property_value为json数组形式,包含两个元素,如[10,20]或["2015-07-10","2015-07-11"] |
| within | 用于地理位置分析,在某个范围内。暂不支持 |
数据类型和operator对应关系
| 数据类型 | 支持的operator |
|---|---|
| string | eq、ne、lt、lte、gt、gte、contains、not_contains、in、between |
| number | eq、ne、lt、lte、gt、gte、in、between |
| geo | within 暂不支持 |
3.1.6 Having
Having用于对聚合操作之后的结果进行过滤,比如某一个count聚合操作之后,只想筛选出count数量大于N的记录,这种情况就需要having。Having本质上也是一种filter,但与前面介绍的filter的区别在于,filter是基于原始表的列进行单行的过滤,而having是对聚合操作后的表进行过滤,因此having后面的filter的属性名必须是group by列或者是聚合列。
Having结构定义如下:
"having": {
"relation": "AND",
"agg_filters": [
{
"relation" : "OR",
"property_filters": [
{
"property_name": "gender",
"operator": "eq",
"property_value": "male"
},
{
"property_name": "age",
"operator": "gte",
"property_value": 18
}
]
},
{
"property_filters": [
{
"property_name": ["COUNT", "*"],
"operator": "gte",
"property_value": 10000
}
]
}
]
}
可以看到这个结构和之前的filter几乎完全一样,结构上唯一的区别在于property_name,在之前filters中,property_name只能是一个string,在这里,还可以是一个由两个元素组成的数组,第一个元素代表聚合操作,第二个元素代表对哪个列进行聚合操作。
注:Having所有的property_name,都必须是group by列或者是聚合操作。
3.1.7 分析接口
Inspire提供了丰富的分析接口,从简单的聚合统计,到复杂的模型分析等,本章节将详细讲解各个分析功能。
3.1.7.1 Count
Count用于统计事件的数量,在构造请求时可以指定一系列参数。
方法
URL中的方法为count。
请求
所有的请求参数均通过HTTP的body传入,并且为json格式。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| collection | string | 是 | 事件数据集名 |
| timezone | string | 否 | 查询指定的时区,比如东八区值为Asia/Shanghai, 默认为UTC |
| timeframe | json object或string | 否 | 分析该timeframe窗口内的数据,绝对时间格式为包含start和end的struct,相对时间为相应格式的字符串 |
| interval | string | 否 | 用于从时间维度细化分析结果的聚合粒度,比如按小时、天、月进行分析统计 |
| actor_identifier_property | string | 否 | 事件表中用于和actor表中id列进行join的列名 |
| object_identifier_property | string | 否 | 事件表中用于和object表中id列进行join的列名 |
| interval | string | 否 | 用于从时间维度细化分析结果的聚合粒度,比如按小时、天、月进行分析统计 |
| group_by | array | 否 | 用于从属性维度细化分析结果的聚合粒度,比如按性别男、女进行分析统计 |
| group_by_type | array | 否 | group by列的类型,取值为actor,object或者event |
| filters | json object | 否 | 用于在分析过程中进行事件数据的过滤 |
| order_by | json object | 否 | 用于对结果进行排序 |
| limit | integer | 否 | 限制返回的结果数 |
| having | json object | 否 | 对聚合结果进行过滤 |
响应
返回结果为json格式的数组,数组的每一个item为一个时间单位的结果,如果在查询请求中指定了group_by,在返回的result中也会包含group字段,如下:
{
"result": [
{
"start_time": "2015-06-29 00:00:00.000000+0800",
"end_time": "2015-06-30 00:00:00.000000+0800",
"group": "on",
"result": 100
},
{
"start_time": "2015-06-30 00:00:00.000000+0800",
"end_time": "2015-07-01 00:00:00.000000+0800",
"group": "on",
"result": 25
}
]
}
注:当前,对于没有结果数据的interval,response中会自动补充零值。
示例
curl -X POST http://127.0.0.1:10000/zc-queryengine/v1/count \
-H "Content-Type:text/json" \
-H "X-Zc-Major-Domain-Id:1" \
-d `{
"collection": "test",
"timezone" : "Asia/Shanghai",
"timeframe": "previous_40_days",
"interval": "every_1_days",
"group_by": ["action"],
"filters": [
{
"property_name": "action",
"operator": "eq",
"property_value": "on"
}
]
}`
3.1.7.2 Count unique
Count unique用于统计不同事件的数量,即去重后统计,在构造请求时可以指定一系列参数。
方法
URL中的方法为count_unique。
请求
所有的请求参数均通过HTTP的body传入,并且为json格式。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| collection | string | 是 | 事件数据集名 |
| property | string | 是 | 对哪个列进行count unique |
| timezone | string | 否 | 查询指定的时区,比如东八区值为Asia/Shanghai, 默认为UTC |
| timeframe | json object或string | 否 | 分析该timeframe窗口内的数据,绝对时间格式为包含start和end的struct,相对时间为相应格式的字符串 |
| interval | string | 否 | 用于从时间维度细化分析结果的聚合粒度,比如按小时、天、月进行分析统计 |
| actor_identifier_property | string | 否 | 事件表中用于和actor表中id列进行join的列名 |
| object_identifier_property | string | 否 | 事件表中用于和object表中id列进行join的列名 |
| interval | string | 否 | 用于从时间维度细化分析结果的聚合粒度,比如按小时、天、月进行分析统计 |
| group_by | array | 否 | 用于从属性维度细化分析结果的聚合粒度,比如按性别男、女进行分析统计 |
| group_by_type | array | 否 | group by列的类型,取值为actor,object或者event |
| filters | json object | 否 | 用于在分析过程中进行事件数据的过滤 |
| order_by | json object | 否 | 用于对结果进行排序 |
| limit | integer | 否 | 限制返回的结果数 |
| having | json object | 否 | 对聚合结果进行过滤 |
响应
同count。
示例
类似count。
3.1.7.3 Count last version
Count last version,主要用于事件的主体会进行升级的场景,如APP的升级、固件的OTA等。这类事件在每次发生时,其版本属性都可能不同。但是用户有统计不同版本数量的需求,因此我们提供了该分析模型。
注:Inspire支持自定义Profile类型后,该分析方法作用不大了,类似统计这种版本会升级的数量,直接从Profile中统计即可。
方法
URL中的方法为count_last_version。
请求
所有的请求参数均通过HTTP的body传入,并且为json格式。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| collection | string | 是 | 事件数据集名 |
| timezone | string | 否 | 查询指定的时区,比如东八区值为Asia/Shanghai, 默认为UTC |
| property | string | 是 | 需要统计版本数量的属性,如device.id |
| version_property | string | 是 | 指定具有版本特性的属性,对于同一设备,该属性也可能不同,如ota_version |
| timeframe | json object或string | 否 | 分析该timeframe窗口内的数据,绝对时间格式为包含start和end的struct,相对时间为相应格式的字符串 |
| interval | string | 否 | 用于从时间维度细化分析结果的聚合粒度,比如按小时、天、月进行分析统计 |
| group_by | string | 否 | 用于从属性维度细化分析结果的聚合粒度,比如按性别男、女进行分析统计 |
| group_by_type | array | 否 | group by列的类型,取值为actor,object或者event |
| filters | array | 否 | 用于在分析过程中进行事件数据的过滤 |
| order_by | struct | 否 | 用于对结果进行排序 |
| having | json object | 否 | 对聚合结果进行过滤 |
| limit | integer | 否 | 限制返回的结果数 |
响应
同count。
示例
类似count。
3.1.7.4 Max
Max用于查找被指定属性上的最大值,这里被查找属性列必须为int或float型。如统计“一天内,用户使用空调的最高温度”。
方法
URL中的方法为max。
请求
所有的请求参数均通过HTTP的body传入,并且为json格式。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| collection | string | 是 | 事件数据集名 |
| property | string | 是 | 需要统计最大值的属性,如price |
| timezone | string | 否 | 查询指定的时区,比如东八区值为Asia/Shanghai, 默认为UTC |
| timeframe | json object或string | 否 | 分析该timeframe窗口内的数据,绝对时间格式为包含start和end的struct,相对时间为相应格式的字符串 |
| interval | string | 否 | 用于从时间维度细化分析结果的聚合粒度,比如按小时、天、月进行分析统计 |
| actor_identifier_property | string | 否 | 事件表中用于和actor表中id列进行join的列名 |
| object_identifier_property | string | 否 | 事件表中用于和object表中id列进行join的列名 |
| interval | string | 否 | 用于从时间维度细化分析结果的聚合粒度,比如按小时、天、月进行分析统计 |
| group_by | array | 否 | 用于从属性维度细化分析结果的聚合粒度,比如按性别男、女进行分析统计 |
| group_by_type | array | 否 | group by列的类型,取值为actor,object或者event |
| filters | struct | 否 | 用于在分析过程中进行事件数据的过滤 |
| order_by | struct | 否 | 用于对结果进行排序 |
| having | json object | 否 | 对聚合结果进行过滤 |
| limit | integer | 否 | 限制返回的结果数 |
响应
同count。
示例
类似count。
3.1.7.5 Min
Min用于查找被指定属性上的最小值,这里被查找属性列必须为int或float型。如统计“一天内,用户使用空调的最低温度”。
方法
URL中的方法为min。
请求
同Max。
响应
同Max。
示例
类似Max。
3.1.7.6 Sum
Sum用于统计给定的某个属性上的总和,这里被统计属性列必须为int或float型。如统计“一天内,插座上统计到的耗电总量”。
方法
URL中的方法为sum。
请求
同Max。
响应
同Max。
示例
类似Max。
3.1.7.7 Average
Average用于查找被指定属性上的平均值,也可称为mean,这里被统计属性列必须为int或float型。如统计“一天内,用户使用空调的平均温度”。
方法
URL中的方法为average。
请求
同Max。
响应
同Max。
示例
类似Max。
3.1.7.8 Cohort
Cohort表示群组分析,把具有相同属性的事物(如人、设备等)分为一个群组。Cohort可用于在不同的群组之间,在不同的方面进行对比分析,如时间维度、行为维度等。比如:
- 我们按设备OTA版本来划分cohort,对比不同版本在一段时间内的使用次数
- 我们按销售渠道来划分cohort,对比不同渠道销售的设备在一段时间内的使用情况
方法
URL中的方法为cohort。
请求
所有的请求参数均通过HTTP的body传入,并且为json格式。整个cohort分析的请求由三部分构成,第一部分是时区信息,第二部分用于划分群组(cohorts),最后一部分用于定义在划分好的群组上进行的聚合统计,以达到最终结果(criteria)。
时区部分如下:
"timezone": "Asia/Shanghai"
cohorts部分为json数组形式,数组中的每一item定义一个具体的cohort。如下所示:
"cohorts": [
{
"collection": "purchase",
"property": "user.id",
"timeframe": {
"start": "2015-07-15 17:45:00.000000+0800",
"end": "2015-07-15 17:47:00.000000+0800"
},
"filters": [
{
"property_name": "channel",
"operator": "eq",
"property_value": "jd"
}
]
},
{
"collection": "purchase",
"property": "user.id",
"timeframe": {
"start": "2015-07-15 17:45:00.000000+0800",
"end": "2015-07-15 17:47:00.000000+0800"
},
"filters": [
{
"property_name": "channel",
"operator": "eq",
"property_value": "taobao"
}
]
}
]
cohort部分参数说明
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| collection | string | 是 | 事件数据集名,不同的cohort可以是不同的collection |
| property | string | 是 | 需要统计的属性,该属性用于标识每个cohort中的actor |
| timeframe | struct | 否 | 分析该timeframe窗口内的数据,只支持绝对时间 |
| filters | array | 否 | 用于在分析过程中进行事件数据的过滤。cohort不支持group_by,如果要按属性区分cohort,可以在不同的cohort中指定不同的filters |
criteria部分为json结构形式,如下所示:
"criteria": {
"collection": "operate",
"cohort_property": "user.id",
"aggr_property": "user.id",
"aggregation": "count",
"interval": "every_1_hours",
"timeframe": {
"start": "2015-07-15 17:45:00.000000+0800",
"end": "2015-07-15 19:50:00.000000+0800"
},
"filters": [
{
"property_name": "type",
"operator": "eq",
"property_value": "app"
}
]
}
criteria部分参数说明
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| collection | string | 是 | 事件数据集名,可以与cohort部分的collection不同 |
| cohort_property | string | 是 | cohort中用于标识actor的属性,其值域必须与cohort部分的property相同,如user.id |
| aggr_property | string | 是 | 在每一个cohort上进行聚合分析的属性,如price |
| aggregation | string | 是 | 具体的聚合方法,支持count、count_unique、max、min、avg |
| timeframe | struct | 是 | 分析该timeframe窗口内的数据,只支持绝对时间 |
| interval | string | 否 | 用于从时间维度细化分析结果的聚合粒度,比如按小时、天、月进行分析统计 |
| filters | array | 否 | 用于在分析过程中进行事件数据的过滤。cohort不支持group_by,如果要按属性区分cohort,可以在不同的cohort中指定不同的filters |
响应
cohort的分析结果也分为两部分,第一部分为cohort的结果,第二部分为具体的criteria。cohort部分为每个群组的统计结果值(count_unique),criteria部分为我们想要得到的每个时间单位的结果。可以看到,criteria_value为一个二维数组,第一维和cohort对应,也就是每一个cohort对应一个criteria,第二维为每一个cohort在不同时间单位内的聚合值,如下所示:
{
"result": {
"cohort_value":[
3,
1
],
"criteria_value":[
[
{
"value": 1,
"start_time": "2015-07-15 17:00:00.000000+0800",
"end_time": "2015-07-15 18:00:00.000000+0800"
},
{
"value": 1,
"start_time": "2015-07-15 19:00:00.000000+0800",
"end_time": "2015-07-15 20:00:00.000000+0800"
}
],
[
{
"value":2,
"start_time": "2015-07-15 19:00:00.000000+0800",
"end_time": "2015-07-15 20:00:00.000000+0800"
}
]
]
}
}
示例
我们想要对比分析在一定时间段内,通过不同的售货渠道,如jd、taobao销售出去的设备,在一段时间内使用app操作的次数,可以构造如下的cohort分析请求,便能得到上述的response。
curl -X POST http://127.0.0.1:10000/zc-queryengine/v1/cohort \
-H "Content-Type:text/json" \
-H "X-Zc-Major-Domain-Id:1" \
-d `{
"timezone": "Asia/Shanghai",
"cohorts": [
{
"collection": "purchase",
"property": "user.id",
"timeframe": {
"start": "2015-07-15 17:45:00.000000+0800",
"end": "2015-07-15 17:47:00.000000+0800"
},
"filters": [
{
"property_name": "channel",
"operator": "eq",
"property_value": "jd"
}
]
},
{
"collection": "purchase",
"property": "user.id",
"timeframe": {
"start": "2015-07-15 17:45:00.000000+0800",
"end": "2015-07-15 17:47:00.000000+0800"
},
"filters": [
{
"property_name": "channel",
"operator": "eq",
"property_value": "taobao"
}
]
}
],
"criteria": {
"collection": "operate",
"cohort_property": "user.id",
"aggr_property": "user.id",
"aggregation": "count",
"interval": "every_1_hours",
"timeframe": {
"start": "2015-07-15 17:45:00.000000+0800",
"end": "2015-07-15 19:50:00.000000+0800"
},
"filters": [
{
"property_name": "type",
"operator": "eq",
"property_value": "app"
}
]
}
}`
3.1.7.9 Funnel
Funnel analysis俗称漏斗分析。funnel用于描述用户为达成某一最终目标而历经的流程/路径/步骤。在做漏斗分析的过程,我们能知道用户在每一步的存留情况,进而知道最终的转化率。
如我们可以跟踪某一款设备从出售到最终操控等一系列流程: 浏览设备信息-->购买设备-->激活设备-->用app操控设备
分析步骤大致如下:
- 统计浏览过设备信息的唯一用户数;
- 在浏览过设备信息的用户基础上,统计购买了设备的用户数;
- 在购买了设备的用户基础上,统计激活设备的用户数;
- 在激活设备的用户基础上,统计使用app控制设备的用户数。
通过funnel分析,我们可以知道每一个步骤的用户完成数,因此这里的每一个步骤对funnel analysis来说,是非常重要的属性,下面先详细介绍step。
step
前面我们知道漏斗分析是为了分析某一群组在不同阶段的留存情况,这里的每一阶段称之为step。第一个step决定了起始的数据集(如人群、设备群)。每一个step包含一些属性,如下:
- 事件数据集:用于表明该step要分析的数据的数据集(collection),每一个step可以是不同的collection。
- 事件属性:可唯一标识一个事件数据的属性,通常情况下为用户id、设备id等。
- timeframe:在这一步骤中,需要分析的时间段,第一个step必须指定。其它step可选,如果不指定则继承step 1的timeframe。
由于漏斗分析是分析多个步骤,因此,step需要以json数组形式定义,如下:
"steps": [
{
"collection": "purchase",
"property": "user.id",
"timeframe":"this_15_days"
},
{
"collection": "activate",
"property": "user.id",
"timeframe": "this_15_days"
},
{
"collection": "operate",
"property": "user.id",
"filters": [
{
"property_name": "type",
"operator": "eq",
"property_value": "app"
}
]
}
]
具体每一步的参数说明
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| collection | string | 是 | 事件数据集名,每一个step的collection不同 |
| property | string | 是 | 用于统计的属性,每一个step的property由于其所属collection可能不同因而名字可以不同,但其值域需要相同,如user.id,uid等 |
| timeframe | string | 否 | 分析该timeframe窗口内的数据。第一个step必须指定,后续step可选,如果不指定则继承第一个step的timeframe |
| filters | array | 否 | 用于在分析过程中进行事件数据的过滤。cohort不支持group_by,如果要按属性区分cohort,可以在不同的cohort中指定不同的filters |
方法
URL中的方法为funnel。
请求
定义好json格式的steps,作为请求body发起查询请求即可。
响应
Funnel analysis分析结果由两部分组成,一部分是每一step的结果数据,另一部分是查询时定义的具体step,方便可视化展示使用,如:
{
"result": {
"result": [
4,
3,
3
],
"steps": [
{
"collection": "purchase",
"property": "user.id",
"start_time": "2015-07-09 00:00:00.000000+0800",
"end_time": "2015-07-23 22:06:19.432754+0800"
},
{
"collection": "activate",
"property": "user.id",
"start_time": "2015-07-09 00:00:00.000000+0800",
"end_time": "2015-07-23 22:06:19.432766+0800"
},
{
"collection": "operate",
"property": "user.id",
"start_time": "2015-07-09 00:00:00.000000+0800",
"end_time": "2015-07-23 22:06:19.432770+0800"
}
]
}
}
示例
这里我们定义了3个step,第一个step定义了在15天内购买了设备的用户;第二个step定义了第一个step所选定的用户在15天内激活设备的用户;第三个step定义了激活了设备,并且用app操作的用户。构造如下的分析,便能得到类似上述的response:
curl -X POST http://127.0.0.1:10000/zc-queryengine/v1/funnel \
-H "Content-Type:text/json" \
-H "X-Zc-Major-Domain-Id:1" \
-d `{
"timezone": "Asia/Shanghai",
"steps": [
{
"collection": "purchase",
"property": "user.id",
"timeframe":"this_15_days"
},
{
"collection": "activate",
"property": "user.id",
"timeframe": "this_15_days"
},
{
"collection": "operate",
"property": "user.id",
"filters": [
{
"property_name": "type",
"operator": "eq",
"property_value": "app"
}
]
}
]
}`
3.1.7.10 Session
由于智能硬件种类非常多,绝大部分产生的数据都可以看作事件数据,即在某一时刻发生的,并无上下文,比如智能豆浆机的使用。但也有一些例外的场景,如智能空气净化器,厂商可能想统计设备的开机时长。
像统计开机时长这类需求,可抽象为统计设备在线/运行时长,如果在设备每次关机时将本次运行时长数据汇报给云端,则这类属于仍然是一个简单的事件数据。但是如果设备只是单纯的汇报一个关机事件,并不把运行时长汇报上来,则这类数据具有session特征,其session的生命期为[设备开机时刻~设备关机时刻]。
Inspire提供的session分析,会在给定的时间窗口(由timeframe和interval指定)内,按设备统计平均值、最大值、最小值以及分析操控次数、时间段分布等情况。比如今天共有2台设备,设备1被控制了3次,时长分别为2,3,3分钟,则该设备当天总的控制时长为2+3+3=8分钟。设备2被控制了4次,时长分别为3,4,2,3分钟,则该设备当天总的控制时长为3+4+2+3=12分钟。那么session分析的结果返回:平均时长:(8+12)/ 2 = 10分钟;最大时长12分钟;最小时长8分钟;设备数为2;操控次数为7已经详细的时间段分布。
注:分析请求中指定的时长单位为秒,分析结果中的时长(平均、最大、最小时长)单位也为秒。
这里,我们讨论几个特殊场景,如用户的操作事件如下(已按event.timestamp排序):
event.timestamp | device.id | op
---------------------+-----------+-----------
2015-07-16 08:05:28 | 333 | start
2015-07-16 09:05:28 | 333 | end
2015-07-16 09:15:28 | 333 | start
2015-07-16 09:19:28 | 222 | end
2015-07-16 09:29:28 | 222 | start
2015-07-16 09:30:28 | 333 | end
2015-07-16 09:39:28 | 222 | end
2015-07-16 09:49:28 | 222 | start
2015-07-16 19:49:28 | 111 | start
2015-07-16 19:52:28 | 111 | start
2015-07-16 19:55:28 | 111 | heartbeat
2015-07-16 19:59:28 | 111 | end
2015-07-16 20:00:28 | 111 | start
2015-07-16 20:10:28 | 111 | end
场景1:不完整的session,在给定时间窗口内缺少end_tag
我们看上面的event data,如果按小时(hour)粒度进行session分析,那么在08小时内,只有设备333记录了一条start event:
2015-07-16 08:05:28 | 333 | start
说明设备333在该小时内一直运行直到该小时结束。对于该类case,AbleCloud计算设备333在08小时内的session时长为下一个时间窗口的起始时刻 - start事件时刻,即 2015-07-16 09:00:00 - 2015-07-16 08:05:28 = 3272 s
场景2:不完整的session,在给定时间窗口内缺少start_tag
同样,如果按小时(hour)粒度进行session分析,那么在09小时内,设备333共触发了三条event:end、start、end
2015-07-16 09:05:28 | 333 | end
2015-07-16 09:15:28 | 333 | start
2015-07-16 09:30:28 | 333 | end
第一条为end_tag,也就是在09小时这一时间窗口内,设备333的第一个session只有结束标识,说明设备333在09小时前就已经启动。对于该类case,AbleCloud计算用户的这种session为end事件时刻 - 上一个时间窗口的结束时刻,即2015-07-16 09:05:28 - 2015-07-16 09:00:00 = 328 s。设备333在该时间窗口内的另一个session是完整的,其时长为2015-07-16 09:30:28 - 2015-07-16 09:15:28 = 900 s。所以设备333在09小时内的总的session长度为328 + 900 = 1228 s。
场景3:触发重复的start事件
用户很大可能会触发重复的操作事件,AbleCloud在分析session时,会对重复事件进行去重处理。 如果按小时(hour)粒度进行session分析,那么设备111就有重复的start事件:
2015-07-16 19:49:28 | 111 | start
2015-07-16 19:52:28 | 111 | start
2015-07-16 19:55:28 | 111 | heartbeat
2015-07-16 19:59:28 | 111 | end
2015-07-16 20:00:28 | 111 | start
2015-07-16 20:10:28 | 111 | end
对于重复的start事件,我们将选取第一个start作为该session的起始时刻,然后过滤重复的start事件直到找到对应的end事件或到达该时间窗口内的末尾处。如上面用户1的第一个session,其时长为2015-07-16 19:59:28 - 2015-07-16 19:49:28 = 600 s。期间有一条heartbeat事件,我们把它当做start事件处理。
场景4:触发重复的end事件
类似场景3,只不过AbleCloud在进行end事件去重时,先用第一个end事件结束上一个session,然后再过滤重复的end事件。
方法
URL中的方法为session。
请求
{
"collection": "action",
"timezone": "Asia/Shanghai",
"timeframe": "this_1_months",
"interval": "every_1_hours",
"object_property": "device.id",
"action_property": "op",
"start_tag": [
"start",
"heartbeat"
],
"end_tag": "end",
"session_time_slice": [
600,
1200,
2500
],
"object_time_slice": [
600,
1200,
2500
]
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| collection | string | 是 | 事件数据集名,如"operation" |
| timezone | string | 否 | 时区信息,东八区是Asia/Shanghai |
| object_property | string | 是 | 用于标识事件发生主体的属性,如“device.id” |
| action_property | string | 是 | 用于标识session动作的的属性,如操控“op” |
| start_tag | array | 是 | 用于标识session的开始,支持多个标签以支持心跳事件,如["start","heartbeat"] |
| end_tag | string | 是 | 用于标识session结束,如"end" |
| timeframe | struct或string | 否 | 分析该timeframe窗口内的数据,绝对时间格式为包含start和end的struct,相对时间为相应格式的字符串 |
| interval | string | 否 | 用于从时间维度细化分析结果的聚合粒度,比如按小时、天、月进行分析统计 |
| session_time_slice | array | 否 | 用于指定不同的单个session时长,如果指定,该分析会统计落在不同时长内的session数,单位为秒 |
| object_time_slice | array | 否 | 用于指定不同的对象在分析时间单位内总的session时长,如果指定,该分析会统计落在不同时长内的session数,单位为秒 |
| filters | array | 否 | 用于在分析过程中进行事件数据的过滤。cohort不支持group_by,如果要按属性区分cohort,可以在不同的cohort中指定不同的filters |
注:session_time_slice指定的是单个session的时长区间,如按天分析设备使用情况,该参数指定的是设备的每一次操作的时长分布情况。object_time_slice指定的是每个操作对象在给定时间内总的session时长,如按天分析设备使用情况,该参数指定的是每一个设备一天使用的总的时长分布情况。
响应
返回值为json数组格式,每一个数组item为每一个时间单位内的object数,session数,平均session时长,最大session时长,最小session时长,以及其时间窗口的起始/结束时间。同时,如果在查询请求中指定了不同的session时长(单位为秒),response中将根据请求中的时长,分别统计落在时长区域内的session数,时长区间取值为[start, end),如[0, 600)表示0s <= session时长 < 600s,session的时长分析结果分为两类,分别对应于请求中的session_time_slice和object_time_slice,如下:
{
"result": [
{
"start_time": "2015-07-16 08:00:00.000000+0800",
"end_time": "2015-07-16 09:00:00.000000+0800",
"object_number": 1,
"session_number": 1,
"average_length": 3272,
"max_length": 3272,
"min_length": 3272,
"session_slice_result": [
{
"600": 0
},
{
"1300": 0
},
{
"2500": 0
},
{
"other": 1
}
],
"object_slice_result": [
{
"600": 0
},
{
"1300": 0
},
{
"2500": 0
},
{
"other": 1
}
]
},
{
"start_time": "2015-07-16 09:00:00.000000+0800",
"end_time": "2015-07-16 10:00:00.000000+0800",
"object_number": 2,
"session_number": 5,
"average_length": 1814,
"max_length": 2400,
"min_length": 1228,
"session_slice_result": [
{
"600": 1
},
{
"1300": 4
},
{
"2500": 0
},
{
"other": 0
}
],
"object_slice_result": [
{
"600": 0
},
{
"1300": 0
},
{
"2500": 2
},
{
"other": 0
}
]
},
{
"start_time": "2015-07-16 19:00:00.000000+0800",
"end_time": "2015-07-16 20:00:00.000000+0800",
"object_number": 1,
"session_number": 1,
"average_length": 600,
"max_length": 600,
"min_length": 600,
"session_slice_result": [
{
"600": 0
},
{
"1300": 1
},
{
"2500": 0
},
{
"other": 0
}
],
"object_slice_result": [
{
"600": 0
},
{
"1300": 1
},
{
"2500": 0
},
{
"other": 0
}
]
},
{
"start_time": "2015-07-16 20:00:00.000000+0800",
"end_time": "2015-07-16 21:00:00.000000+0800",
"object_number": 1,
"session_number": 1,
"average_length": 600,
"max_length": 600,
"min_length": 600,
"session_slice_result": [
{
"600": 0
},
{
"1300": 1
},
{
"2500": 0
},
{
"other": 0
}
],
"object_slice_result": [
{
"600": 0
},
{
"1300": 1
},
{
"2500": 0
},
{
"other": 0
}
]
}
]
}
注:如果对设备的使用情况进行分析,响应中的session_number,其值等同于设备的使用次数。
示例
这里,我们的需求如下:在最近一个月内,按每小时粒度分析用户对设备控制的时长分布情况以及设备的操控情况,可构造如下分析请求:
curl -X POST http://127.0.0.1:10000/zc-queryengine/v1/session \
-H "Content-Type:text/json" \
-H "X-Zc-Major-Domain-Id:1" \
-d `{
"collection": "action",
"timezone":"Asia/Shanghai",
"timeframe": "this_1_months",
"interval": "every_1_hours",
"object_property": "device.id",
"action_property": "op",
"start_tag": [
"start",
"heartbeat"
],
"end_tag": "end",
"session_time_slice": [
600,
1300,
2500
],
"object_time_slice": [
600,
1200,
2500
]
}`
运行该分析请求,则能得到类似上节的response。
3.1.7.11 Retention
留存率分析,数据运营人员经常需要分析用户的留存率,比如第一天使用了他们的产品,第二天第三天也使用了产品,那说明这款产品做的好,用户反复使用,对用户有粘性,用户没有流失,即留存率高。留存率分析用来做这事。
方法
URL中的方法为retention。
请求
{
"timezone": "Asia/Shanghai",
"timeframe": {
"start": "2015-10-15 00:00:00.000000+0800",
"end": "2015-10-19 00:00:00.000000+0800"
}
"retention_timeframe": "3_days",
"object_filters":
"actor_filters":
"initial" : {
"collection": "device_activate",
"retention_property": "deviceId",
"filters": {
"agg_filters": [
{
"property_filters": [
{
"property_name": "region",
"operator": "eq",
"property_value": "bj"
}
]
}
}
},
"subsequent" : {
"collection": "device_bind",
"retention_property": "deviceId"
}
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| collection | string | 是 | 事件数据集名,如"device_activate" |
| timeframe | string或者struct | 是 | 分析该timeframe窗口内的数据,绝对时间格式为包含start和end的struct,相对时间为相应格式的字符串 |
| retention_property | string | 是 | 用于标识留存统计的目标属性,如“deviceId” |
| retention_timeframe | string | 是 | 比如7日留存,1个月留存等 |
| initial | struct | 是 | 初始行为 |
| subsequent | struct | 是 | 后续行为 |
| timezone | string | 否 | 时区信息,东八区是Asia/Shanghai,不填就是UTC |
响应
{
"result": [
{
“count”: 100,
"start_time": "2015-10-15 00:00:00.000000+0800",
"retentions" : [
{
"count": 10,
"retention_percent": 8.3
},
{
"count": 20,
"retention_percent": 16.6
},
{
"count": 5,
"retention_percent": 4.15
}
]
},
{
"count":80,
"start_time": "2015-10-16 00:00:00.000000+0800",
"retentions" : [
{
"count": 18,
"retention_percent": 9.2
},
{
"count": 28,
"retention_percent": 18.6
}
]
},
{
"count": 70,
"start_time": "2015-10-17 00:00:00.000000+0800",
"retentions" : [
{
"count": 18,
"retention_percent": 9.2
}
]
}
]
}
示例
2015年10月15日到2015年11月15日期间,激活的设备在7日内被绑定的百分比以及个数。
curl -X POST http://127.0.0.1:10000/zc-queryengine/v1/retention \
-H "Content-Type:text/json" \
-H "X-Zc-Major-Domain-Id:1" \
-d `{
"timezone": "Asia/Shanghai",
"analysis_timeframe": {
"start": "2015-10-15 00:00:00.000000+0800",
"end": "2015-11-15 00:00:00.000000+0800"
}
"retention_timeframe": "7_days",
"retention_property": "deviceId",
"initial" : {
"collection": "device_activate"
},
"subsequent" : {
"collection": "device_bind"
}
}`
3.1.7.12 Conversion
即转化分析,可通过funnel分析得到。
3.1.7.13 Distribution
分布分析,有些统计需求需要对聚合之后的结果再分割为若干个区间,然后计算落在每个区间里的个数,比如,统计一段时间内的设备使用次数,0~100有多少个设备,100~500有多少个,大于等于500有多少个。
方法
URL中的方法为distribution。
请求
所有的请求参数均通过HTTP的body传入,并且为json格式。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| collection | string | 是 | 事件数据集名 |
| aggregation | string | 是 | 对数据进行哪种聚合操作, 支持count/count_unique/min/max/avg/sum |
| property | string | 否 | 对那个列进行聚合操作,当聚合操作为count时候,不需要此属性 |
| range | array | 是 | 不同区间内的聚合结果行的个数 |
| timezone | string | 否 | 查询指定的时区,比如东八区值为Asia/Shanghai, 默认为UTC |
| timeframe | json object或string | 否 | 分析该timeframe窗口内的数据,绝对时间格式为包含start和end的struct,相对时间为相应格式的字符串 |
| actor_identifier_property | string | 否 | 事件表中用于和actor表中id列进行join的列名 |
| object_identifier_property | string | 否 | 事件表中用于和object表中id列进行join的列名 |
| group_by | array | 否 | 用于从属性维度细化分析结果的聚合粒度,比如按性别男、女进行分析统计 |
| group_by_type | array | 否 | group by列的类型,取值为actor,object或者event |
| filters | json object | 否 | 用于在分析过程中进行事件数据的过滤 |
| limit | integer | 否 | 限制返回的结果数 |
| unit | string | 否 | 具体到每个用户/设备 |
响应
{
"result": [
{
"range": {
"left":5e-324,
"right":100
},
"count":20,
"groups": [
{
"groupValue": ["beijing"],
"count": 15
}
{
"groupValue": ["shanghai"],
"count": 5
}
]
},
{
"range": {
"left":100,
"right":500
},
"count":40
},
{
"range": {
"left":500,
"right":1.7976931348623157e+308
},
"count":0
}
]
}
示例
统计一段时间内设备使用次数的区间分布:
curl -X POST http://127.0.0.1:10000/zc-queryengine/v1/query_save \
-H "Content-Type:text/json" \
-H "X-Zc-Major-Domain-Id:1" \
-d `{
"collection": "device_operate",
"aggregation": "COUNT",
"range":[100,500],
"timezone": "Asia/Shanghai",
"timeframe": {
"start":"2015-10-01 00:00:00.000000+0800",
"end":"2015-10-03 00:00:00.000000+0800"
}
}`